Анализ текстов конкурентов перед написанием контента
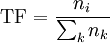
Пришла пора применить знания, полученные на занятии про написание контента, на практике.
Дабы облегчить себе жизнь и своим конкурентам выберу очень животрепещущую тему: учебный запрос :)
Немного теории про применяемые термины:
Без вкуривания в эту часть всё остальное читать возможно бессмысленно...
Статистическая мера текста - TF-IDF
TF выражает отношение вхождений отдельно взятого слова к общему количеству слов в отдельно взятом документе - частота слова
DF - частота документа - выражается отношением общего числа документов с конкретным ключевым словом к числу документов вообще. В данном случае число документов вообще - это общее количество проиндексированных поисковой системой страниц.
IDF - это DF вверх ногами
Мера TF-IDF позволяет оценить вес ключевого слова во всех проиндексированных поисковой системой страницах.
Формулы (стибрено с википедии):
![]() , где ni - число вхождений слова в документ, сумма в знаменателе - общее число слов в документе
, где ni - число вхождений слова в документ, сумма в знаменателе - общее число слов в документе
 , где |D| - количество документов, а хрень в знаменателе символизирует количество документов, в которых встречается искомое ключевое слово
, где |D| - количество документов, а хрень в знаменателе символизирует количество документов, в которых встречается искомое ключевое слово
Но существует достаточно большее число методик расчёта IDF. Самый простой способ - это разделить количество документов, в которых встречается ключевое слово на число документов в поисковой системе.
Для расчёта окончательного веса слова небходимо разделить TF на DF или TF умножить на IDF.
Для чего нужно знать вес слова
Основное назначение - это что-бы наши ключевые слова были самыми весомыми на продвигаемой странице сайта. Побочный эффект - можно увидеть "несовместимость" ключевых слов для продвижения на одной странице сайта из-за кардинально различающихся их весов.
Например слов гроб весит 100 у.е., а слово тапок - всего 5. И из этого следует, что если начать двигать на одной странице гроб с белыми тапками, то текст может тупо выбиваться из закономерностей Ципфа и будет распознан поисковой системой как неестественный с вытекающими из этого фильтрами. Плюс вес белых тапок может раствориться в весе гроба.
Законы Ципфа AKA Зипфа
 Что такое закон Ципфа - это (далее википедия):
Что такое закон Ципфа - это (далее википедия):
эмпирическая закономерность распределения частоты слов естественного языка: если все слова языка (или просто достаточно длинного текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (так называемому ранку этого слова). Например второе по используемости слово встречается примерно в два раза реже, чем первое, третье - в три раза реже, чем первое, и т. д.
Основное знание из этого чуда: существует величина C (ранк-частота), которая более или менее постоянная для текста на определённом языке. Для литературного русского - это 0.06...0.07.
Для расчёта C применяется следующая формула: C=(Частота вхождения слова * Ранг частоты)/Число слов
На изображение посчитанная по закону Зипфа - ранк-частота для топ ключевых слов для топ-10 Яндекса по теме "межкомнатные двери". Как видно из графика в стране полный бардак.
Ципф также установил, что частота и количество слов, входящих в текст с одной частотой, зависимы между собой и только слегка отличаются для разных языков. Выражается понятием количество-частота=количество вхождений слова/частота слова.
Желающие могут попробовать постигнуть знание дальше, а я попытаюсь проанализировать себя и конкурентов по учебному запросу.
Анализ текстов конкурентов по учебному запросу
Первым делом спрашиваю в Яндексе учебный запрос и на попавшуюся топ-4 (остальные бессмысленные) натравливаю любой семантический анализатор текста. Для реальной жизни лучше использовать сайты в топ 20. Не забываем выставить нужный регион в поисковике, если он это умеет.
Беглый анализ показал, что первые четыре страницы в топе Яндекс состоят из 662, 1236, 594 и 995 слов и содержат стоп-слов: 197, 427, 249 и 268. Т.е идеальная длина текста должна быть где-то в районе 900 слов. Не стоит забывать выкинуть из анализа всё, что сидит под
Ранк-частота для страниц сайтов-конкурентов по учебному запросу получилась разная: от 0.003 до 0.035, что вываливается из рекомендуемого для русского языка.
Теперь пройдусь собственно по словам: для анализа буду брать слова с частотой в районе единицы и выше, т.к. дальше идёт откровенный бред не по теме. Попутно накладываю ограничения в виде здравого смысла, ибо тема достаточно загадочная.
Анализирую текст, пришёл к выводу, что помимо всех вариантов написания слов учебный запрос в тексте должны присутствовать слова сайт, поиск/поисковый, seo, продвижение, учёба, курс и лекция. Частота основного запроса от 5 до 9%.
Осталось сесть и написать текст, используя рекомендации выше. А потом потиху следить за конкурентами и вносить коррективы по мере изменения позиций в топе.
Сайты-конкуренты разделились на две кучки - кто-то двигает главную, а кто-то отдельную страницу сайта. Т.е. и для меня можно использовать любую из двух стратегий.
Теперь по структуре страницы. У части это главная блога с лентой, в которой в заголовках размазан учебный запрос, а для остальных это контентная страница со статьёй. У большинства присутствуют изображения.
Написание текста скорее всего доверю бирже копирайта, т.к. похоже что их придётся использоваться в процессе обучения.
Задание копирайтеру
Написать структурированный текст длинной около 900 слов на тему учебный запрос, использовав следующие слова: сайт, поиск/поисковый, seo, продвижение, учёба, курс и лекция.
Словосочетания "учебный запрос" во всех вариациях должно употребляться с частотой около 7%.
Оставить место в тексте для двух-трёх изображений.
Рассуждения на тему тыринга контента
Вышеописанный пример несколько неудачен из-за его пока малой распространённости. Ближе к концу занятий на курсах учебный запрос должен быть в топ-40.
Алгоритм анализа текстов конкурентов.
- Берём топ-20 по поисковой системе. Для родной Беларуси это может быть топ 10.
- Прогоняем через любой анализатор контента. Рекомендуют истио. Не забываем выкинуть то, что сидит в noindex.
- Ныкаем себе следующие данные: длина без пробелов, количество слов и топ-20 слов без стоп-слов (по желанию топ слов можно расширить или уменьшить)
- Считаем среднюю длину текста, выбрасывая то, что очень откровенно отличается от остальных. Для этого дела даже существует специальные формулы, которые я изучал ещё в архитектурно-строительном техникуме на каком-то предмете, связанном со статистикой.
На выходе имеет среднюю длину контента, которая нам нужна. - Следом анализируем количество прямых вхождений кейвордов, тупо заходя на сайты и считая их руками.
На выходе имеет число точных вхождений ключевиков/фраз. - Считаем количество словоформ методом вычитания из данных истио точных вхождений, полученных шагом выше
- Затем получаем наше семантическое ядро. Для этого данные из истио по всем сайтам скармливаем опять-же в истио, отбрасываем те слова, что редко встречаются и получаем собственно ядро.
- Всё. Телемаркет. Осталось написать текст самому или дать задание копирайтеру на базе имеющейся длины текста, количества прямых вхождений и семантического ядра.
Важно. Смотрите на структуру анализируемых сайтов. В моём домашнем задании по теме чётко разделялись две конкурирующие структуры: каталог и текст с картинками. Возможно придётся выбрать один из вариантов структурирования текста или применить оба варианта, но на разных страницах.
PS: Стырено с форума Artox и слегка доработано.
Похожие статьи

Ваш комментарий добавлен!
Он будет размещен после модерации